一些深度学习的训练技巧
Batch Normalization
深度网络学习过程本质就是为了学习数据分布,网络在每次迭代都是去学习适应不同的分布,这样将会大大降低网络的训练速度。前面基层的输入数据的分布放生改变,那么后面基层就会被累计放大下去。BN就是为了解决训练过程中,中间层数据分布发生变化的情况。简单的做法就是在每一层输入的时候,插入一个归一化层,然后再进入网络的下一层。
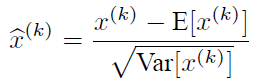
E(x)指每一批训练数据神经元xk的平均值,分母是每一批数据神经元xk激活度的一个标准差。
可是随意变换网络的结构会造成其他层学习到的特征分布被搞坏了,
利用这个公式,可以学习到其他层的特征分布。
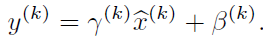
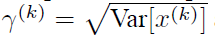
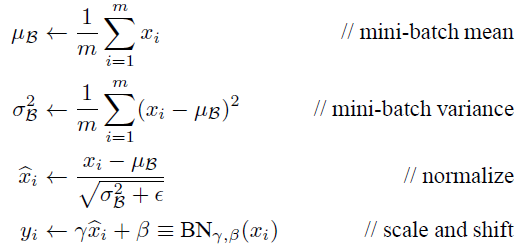
在CNN中,我们可以把每个特征图看成是一个特征处理,就是求取所有样本所对应的一个特征图的所有神经元的平均值、方差,然后对这个神经元做归一化。
Deep Residual Network
深度学习网络并非是deeper and better,残差网络是一个用来训练非常深的深度网络又十分简洁的框架。在神经网络中,需要反向传播来对网络的权重进行调整,但网络很深的时候就会造成每层损失函数求偏导连乘造成精度很小出现误差。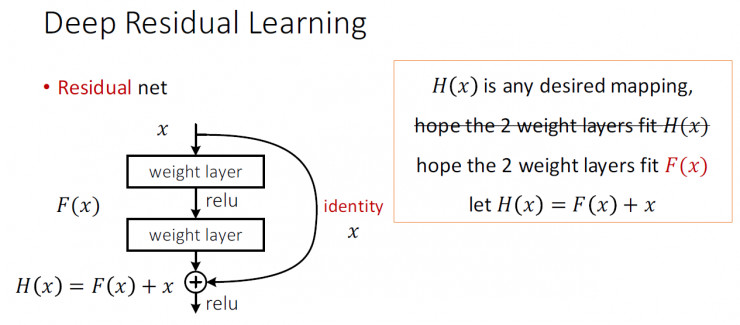
通过求偏导数能看到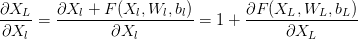
这样就算深度很深,梯度也不会消失。换一个角度看,这也是一种把高阶特征和低阶特征再做融合,从而得到更好的效果。
Dropout
说实话,没有读论文,感觉这个东西非常玄学。
dropout并不依对代价函数的修改,而是在弃权中改变网络自身。Dropout会临时消除网络中一半的隐藏层神经元,同时让输入层和输出层的神经元保持不变。
在前向传播的时候,输入通过修改后的网络,然后反向传播结果。同样通过这个修改后的网络,选择一个新的随机的隐藏神经元的自己进行删除,估计对一个不同的小批量数据的梯度,然后更新权重和偏置。
弃掉不同的神经元集合时,像是在训练不同的网络,最后形成的实质就是由若干个子网络组成的新网络。